Подростки лучше учатся на положительном опыте, чем на отрицательном
|
|||||||||||||


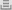


Известно, что подростки более склонны к принятию рискованных решений, чем взрослые. Согласно одной из гипотез, это может быть связано с тем, что подростки используют иные (более простые) алгоритмы обработки информации о результатах своих поступков. Эксперимент, проведенный британскими и итальянскими психологами и нейроэкономистами, подтвердил эту гипотезу. Оказалось, что подростки не хуже взрослых учатся на положительном опыте, но сильно уступают им в способности учиться на отрицательном. Кроме того, взрослые эффективно используют доступную информацию о том, к какому результату привело бы альтернативное решение, а подростки учитывают только реальные результаты своих поступков. Возможно, эти различия связаны с тем, что отделы мозга, отвечающие за обучение на положительном опыте, созревают раньше отделов, обеспечивающих более сложные алгоритмы обучения.
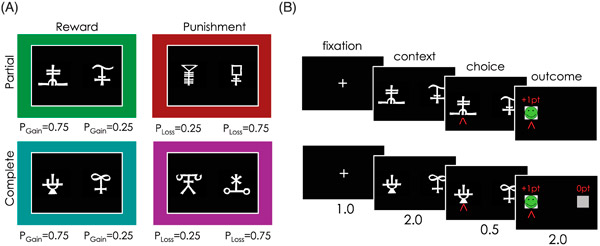
Рис. 1. Дизайн эксперимента. A — варианты выбора, B — последовательность событий в ходе единичного акта обучения. Испытуемому показывали в случайном порядке четыре пары абстрактных символов, из которых нужно было выбрать один. Каждую пару показывали в общей сложности 20 раз, случайным образом меняя положение символов на экране. Каждая пара символов соответствовала одному из четырех обучающих «контекстов». В первом случае (Reward/Partial) один из символов приносил игроку 1 очко с вероятностью 75%, другой — с вероятностью 25%; после принятия решения испытуемый получал информацию о своем выигрыше, но не о том, что он получил бы, выбрав другой символ (B, верхний ряд изображений). Во втором случае (Reward/Complete) всё было так же, за исключением того, что испытуемого информировали еще и том, каков был бы результат в случае принятия альтернативного решения (B, нижний ряд). В третьем и четвертом контекстах вместо награды использовалось наказание: при «правильном» выборе испытуемый терял 1 очко с вероятностью 25%, при «неправильном» — с вероятностью 75%. Рисунок из обсуждаемой статьи в PLoS Computational Biology.
Известно, что подростки более склонны к принятию рискованных решений, чем взрослые. Согласно одной из гипотез, это может быть связано с тем, что подростки используют иные (более простые) алгоритмы обработки информации о результатах своих поступков. Эксперимент, проведенный британскими и итальянскими психологами и нейроэкономистами, подтвердил эту гипотезу. Оказалось, что подростки не хуже взрослых учатся на положительном опыте, но сильно уступают им в способности учиться на отрицательном. Кроме того, взрослые эффективно используют доступную информацию о том, к какому результату привело бы альтернативное решение, а подростки учитывают только реальные результаты своих поступков. Возможно, эти различия связаны с тем, что отделы мозга, отвечающие за обучение на положительном опыте, созревают раньше отделов, обеспечивающих более сложные алгоритмы обучения.
С точки зрения нейробиологии, обучение на положительном и отрицательном опыте — процессы совершенно разные. В первом центральную роль играют «эмоциональные» подкорковые структуры (такие как прилежащее ядро), а второе не обходится без участия отделов коры, связанных с сознательным контролем (дорзальные и дорзолатеральные области префронтальной коры, островок, ростральная часть поясной коры).
С точки зрения алгоритмов, лежащих в основе обучения, картина аналогичная: на положительном опыте учиться проще. Простейший алгоритм обучения с подкреплением — так называемое Q-обучение (Q-learning) — оценивает результат принятых решений по единой шкале в зависимости от благоприятности результата. Этот алгоритм не требует понимания ситуации: для его использования не нужно создавать модель реальности и учитывать контекст, в котором принимается решение. Из-за своей простоты данный алгоритм обеспечивает обучение на положительном опыте эффективнее, чем на отрицательном. Он не может «понять», что в одной ситуации получить ноль очков — это так же хорошо, как в другой ситуации получить одно очко (так будет, например, если в первом случае альтернативой является потеря очка, а во втором — получение нуля очков). Результат оценивается по абсолютной шкале, на которой единица всегда лучше, чем ноль, и поэтому решения, приносящие очко, выучиваются надежнее, чем решения, позволяющие не потерять очко.
Чтобы эффективно учиться избегать неприятностей, нужны более изощренные калькуляции. Здесь уже желательно понимать контекст задачи и оценивать полученный результат не «вообще», а по отношению к тому, что произошло бы в данной конкретной ситуации в случае принятия альтернативного решения.
Группа британских и итальянских психологов и нейроэкономистов опубликовала в журнале PLoS Computational Biology результаты остроумного эксперимента, проливающего свет на механизмы обучения у подростков и взрослых людей. Гипотеза, которую проверяли авторы, состояла в том, что склонность подростков к рискованному поведению объясняется более поздним развитием тех отделов мозга, которые необходимы для сложных алгоритмов обучения, и поэтому подростки полагаются в основном на более примитивный, но зато рано формирующийся алгоритм, близкий к Q-обучению.
В эксперименте приняли участие 18 подростков (каковыми считались лица в возрасте 12–17 лет) и 20 взрослых (от 18 до 32 лет). Схема опыта представлена на рисунке 1. Каждому участнику показывали пары символов, из которых нужно было выбрать один. Символов было всего 8, а пар, соответственно, 4. В каждой паре один символ приносил удачу с вероятностью 75%, а другой — с вероятностью 25%. Каждая пара символов соответствовала одному из четырех «контекстов», различающихся характером подкрепления (награда или наказание) и доступностью дополнительной информации о том, к какому результату привел бы альтернативный выбор. Эффективность обучения оценивалась по частоте, с которой испытуемые выбирали «правильные» символы после обучающей сессии.
Результаты подтвердили ожидания исследователей. Взрослые участники продемонстрировали одинаковую эффективность обучения на положительном и отрицательном опыте. После обучения они уверенно предпочитали символ, приносящий одно очко, спаренному с ним символу, приносящему ноль очков, и столь же уверенно выбирали символ, приносящий ноль очков, если в паре с ним находился символ, отнимающий очко. У подростков результаты обучения оказались разными в этих двух ситуациях. В первом случае, когда выбор делался между 1 и 0, подростки научились делать правильный выбор не хуже взрослых, а во втором, когда выбирать нужно было между 0 и −1, эффективность обучения подростков оказалась заметно ниже.
Кроме того, взрослые извлекли пользу из дополнительной информации о результате альтернативного решения: в вариантах с дополнительной информацией обучение прошло успешнее. Подростки же не смогли использовать эти сведения: эффективность их обучения оказалась одинаковой в вариантах с полной и неполной информацией (рис. 2).
С точки зрения нейробиологии, обучение на положительном и отрицательном опыте — процессы совершенно разные. В первом центральную роль играют «эмоциональные» подкорковые структуры (такие как прилежащее ядро), а второе не обходится без участия отделов коры, связанных с сознательным контролем (дорзальные и дорзолатеральные области префронтальной коры, островок, ростральная часть поясной коры).
С точки зрения алгоритмов, лежащих в основе обучения, картина аналогичная: на положительном опыте учиться проще. Простейший алгоритм обучения с подкреплением — так называемое Q-обучение (Q-learning) — оценивает результат принятых решений по единой шкале в зависимости от благоприятности результата. Этот алгоритм не требует понимания ситуации: для его использования не нужно создавать модель реальности и учитывать контекст, в котором принимается решение. Из-за своей простоты данный алгоритм обеспечивает обучение на положительном опыте эффективнее, чем на отрицательном. Он не может «понять», что в одной ситуации получить ноль очков — это так же хорошо, как в другой ситуации получить одно очко (так будет, например, если в первом случае альтернативой является потеря очка, а во втором — получение нуля очков). Результат оценивается по абсолютной шкале, на которой единица всегда лучше, чем ноль, и поэтому решения, приносящие очко, выучиваются надежнее, чем решения, позволяющие не потерять очко.
Чтобы эффективно учиться избегать неприятностей, нужны более изощренные калькуляции. Здесь уже желательно понимать контекст задачи и оценивать полученный результат не «вообще», а по отношению к тому, что произошло бы в данной конкретной ситуации в случае принятия альтернативного решения.
Группа британских и итальянских психологов и нейроэкономистов опубликовала в журнале PLoS Computational Biology результаты остроумного эксперимента, проливающего свет на механизмы обучения у подростков и взрослых людей. Гипотеза, которую проверяли авторы, состояла в том, что склонность подростков к рискованному поведению объясняется более поздним развитием тех отделов мозга, которые необходимы для сложных алгоритмов обучения, и поэтому подростки полагаются в основном на более примитивный, но зато рано формирующийся алгоритм, близкий к Q-обучению.
В эксперименте приняли участие 18 подростков (каковыми считались лица в возрасте 12–17 лет) и 20 взрослых (от 18 до 32 лет). Схема опыта представлена на рисунке 1. Каждому участнику показывали пары символов, из которых нужно было выбрать один. Символов было всего 8, а пар, соответственно, 4. В каждой паре один символ приносил удачу с вероятностью 75%, а другой — с вероятностью 25%. Каждая пара символов соответствовала одному из четырех «контекстов», различающихся характером подкрепления (награда или наказание) и доступностью дополнительной информации о том, к какому результату привел бы альтернативный выбор. Эффективность обучения оценивалась по частоте, с которой испытуемые выбирали «правильные» символы после обучающей сессии.
Результаты подтвердили ожидания исследователей. Взрослые участники продемонстрировали одинаковую эффективность обучения на положительном и отрицательном опыте. После обучения они уверенно предпочитали символ, приносящий одно очко, спаренному с ним символу, приносящему ноль очков, и столь же уверенно выбирали символ, приносящий ноль очков, если в паре с ним находился символ, отнимающий очко. У подростков результаты обучения оказались разными в этих двух ситуациях. В первом случае, когда выбор делался между 1 и 0, подростки научились делать правильный выбор не хуже взрослых, а во втором, когда выбирать нужно было между 0 и −1, эффективность обучения подростков оказалась заметно ниже.
Кроме того, взрослые извлекли пользу из дополнительной информации о результате альтернативного решения: в вариантах с дополнительной информацией обучение прошло успешнее. Подростки же не смогли использовать эти сведения: эффективность их обучения оказалась одинаковой в вариантах с полной и неполной информацией (рис. 2).
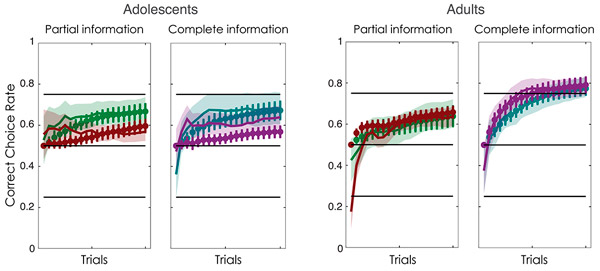
Рис. 2. Рост частоты «правильных» решений в ходе обучения. По горизонтальной оси — порядковый номер испытания (от 1 до 20, так как каждая пара символов демонстрировалась 20 раз). По вертикальной оси — доля правильных решений. Слева подростки (Adolescents), справа взрослые (Adults). Разными цветами обозначены четыре «контекста»; цветовые обозначения те же, что на рис. 1 (зеленый: положительное подкрепление, неполная информация; коричневый: отрицательное подкрепление, неполная информация; сине-зеленый: положительное подкрепление, полная информация; фиолетовый: отрицательное подкрепление, полная информация). Сплошные линии с затененными областями — экспериментальные данные ± стандартная ошибка; линии с доверительными интервалами — результаты моделирования. Для имитации обучения подростков использовалась самая простая модель 1 (см. рис. 3), для взрослых — более сложная модель 3. Рисунок из обсуждаемой статьи в PLoS Computational Biology.
Авторы попытались интерпретировать полученные результаты в рамках представлений об алгоритмах обучения. Для этого они сделали три компьютерные модели (рис. 3). Первая модель соответствует простейшему Q-обучению. Вторая способна учитывать также дополнительные сведения о результатах альтернативного (не выбранного) решения для уточнения представлений о «ценности» этого решения. Третья модель, вдобавок к тому, что умеют две первые, использует данные о результатах обоих решений для того, чтобы поставить полученный выигрыш в адекватный контекст. Эта процедура позволяет алгоритму «понять», что получить ноль очков в ситуации, когда вам грозила потеря очка, это точно так же хорошо, как получить 1 очко в ситуации, когда альтернативой было получение нуля очков.
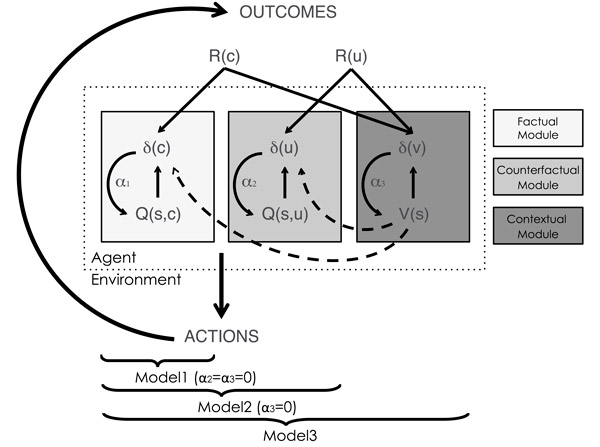
Рис. 3. Три модели обучения, с которыми сравнивались полученные результаты. Модели состоят из трех модулей. Первый из них (Factual module) соответствует простейшему алгоритму обучения с подкреплением — Q-обучению. Он модифицирует величину Q(s, c) — «ценность» или «удачность» выбранного решения c в ситуации s — в зависимости от полученного результата R(c). Второй модуль (Counterfactual module) использует данные о результате альтернативного (не выбранного) решения u для того, чтобы уточнить величину Q(s, u). Третий модуль (Contextual module) использует данные о результатах обоих решений, выбранного (c) и не выбранного (u), чтобы поставить полученный выигрыш в адекватный контекст, соотнеся его с тем, что в принципе можно было получить в данной ситуации s (V(s) — средняя ценность контекста, или усредненная ценность решений c и u). Использование третьего модуля ведет к замене абсолютной шкалы оценки выигрыша на относительную. Из этих трех модулей были составлены три модели. Первая модель включает только модуль 1, вторая — модули 1 и 2, третья — все три модуля. Рисунок из обсуждаемой статьи в PLoS Computational Biology.
Эти три модели прошли точно такой же сеанс «обучения», как и живые участники эксперимента. Оказалось, что ход и конечный результат обучения подростков точнее всего описывается самой простой, первой моделью (Q-обучение). Что касается взрослых, то их обучение точнее всего воспроизводится самой сложной моделью №3.
Таким образом, полученные результаты согласуются с предположением о том, что подростки используют простейший алгоритм обучения с подкреплением, близкий к Q-обучению. Это объясняет, почему подростки хуже учатся на отрицательном подкреплении, чем на положительном. Взрослые используют более сложный алгоритм обучения, включающий дополнительные модули. Это позволяет, во-первых, использовать дополнительную информацию о ценности не выбранного решения, во-вторых, интерпретировать полученный выигрыш в адекватном контексте, оценивая его не «вообще», а по отношению к тому, что в принципе можно было получить в данной ситуации. Благодаря этому взрослые учатся на отрицательном опыте так же эффективно, как и на положительном.
Упрощенный алгоритм обучения, характерный для подростков, согласуется с данными о более позднем созревании отделов мозга, необходимых для реализации более сложных и эффективных алгоритмов. С другой стороны, использование детьми и подростками именно этого простого алгоритма, скорее всего, имеет важный адаптивный смысл. Очень точно прокомментировала обсуждаемую статью в моем блоге одна молодая мама, заметив, что если бы ее ребенок сразу переставал делать всё, на чем он набивает шишки, он бы даже ходить не научился.
Источник: Stefano Palminteri, Emma J. Kilford, Giorgio Coricelli, Sarah-Jayne Blakemore. The Computational Development of Reinforcement Learning during Adolescence // PLoS Computational Biology. V. 12. P. e1004953.
Александр Марков
Таким образом, полученные результаты согласуются с предположением о том, что подростки используют простейший алгоритм обучения с подкреплением, близкий к Q-обучению. Это объясняет, почему подростки хуже учатся на отрицательном подкреплении, чем на положительном. Взрослые используют более сложный алгоритм обучения, включающий дополнительные модули. Это позволяет, во-первых, использовать дополнительную информацию о ценности не выбранного решения, во-вторых, интерпретировать полученный выигрыш в адекватном контексте, оценивая его не «вообще», а по отношению к тому, что в принципе можно было получить в данной ситуации. Благодаря этому взрослые учатся на отрицательном опыте так же эффективно, как и на положительном.
Упрощенный алгоритм обучения, характерный для подростков, согласуется с данными о более позднем созревании отделов мозга, необходимых для реализации более сложных и эффективных алгоритмов. С другой стороны, использование детьми и подростками именно этого простого алгоритма, скорее всего, имеет важный адаптивный смысл. Очень точно прокомментировала обсуждаемую статью в моем блоге одна молодая мама, заметив, что если бы ее ребенок сразу переставал делать всё, на чем он набивает шишки, он бы даже ходить не научился.
Источник: Stefano Palminteri, Emma J. Kilford, Giorgio Coricelli, Sarah-Jayne Blakemore. The Computational Development of Reinforcement Learning during Adolescence // PLoS Computational Biology. V. 12. P. e1004953.
Александр Марков
Смотрите также:
Статьи
Статьи
- Нейробиологические корреляты успешности обучения
М.,2003 - Один шаг в обучении — 100 шагов в развитии: метафора или основополагающий принцип?
Портал психологических изданий PsyJournals.ru